一日体験入社日記
Once upon a time、世の中がまだ平成と呼ばれた頃、一日体験入社する者あり。ということで、2〜3ヶ月ほど前に2社ほど一日入社体験をしてきたので、どんな雰囲気だったのかを書いておきたい。お世話になった会社と利害関係のない第三者として、一日体験入社してみたいけど、どんなひどい目にあうか分からないし勇気も出ないという人たちに少しでも雰囲気が伝えられたらと思う。なぜこういう表現をしているかと言えば、僕が一日入社体験をするまで内心そう思っていたからで、やはり何者でもない人間である僕は、色々とやっていくことにビビってしまうのだが、フリーランスになったからには自分で動かないと案件の芽は育たないという便利な状況に置かれ、運良く体験することが出来た。
なお体験入社後にブログ書いていいですか?とドヤ顔で聞いたくせに、実際にブログを書くのは2〜3ヶ月後というだらしなさは見逃してくれ頼む。
前置きが長くなってしまったが、Repro株式会社と株式会社SmartHRの2社にお世話になったので、それぞれの一日体験入社の流れと感じたことをまとめていく。
Repro株式会社
めちゃめちゃ勢いのあるデジタルマーケティングを生業とする会社。人が増えているらしく、お邪魔した時はかなりオフィスが手狭になっていて、オフィスの増床を予定するぐらいの感じ。PCは自前のを使う。
体験入社までの流れ
- Twitterにて
- オフィスにきませんかというDMもらう
- オフィスに行く日を決める
- オフィスにお邪魔した日
- VPoEとEMに会社や技術スタックの説明を受ける
- 一日体験入社の誘いを受ける
- 体験入社の予定を決める
- Slack上にて
- この時点ぐらいでSlackやGithubのアクセス権限をもらう
- Gentoo Linux使いに突然、Repro Tech Meetupに誘われる
- 体験入社の事前打ち合わせの日
- チームメンバーと事前に顔合わせ
- Gentoo Linux使いに体験入社日までに何をするかと体験入社日に何をするかの説明を受ける
- 暇すぎてReproの人間のような顔をしてRepro Tech Meetupの会場設営を手伝う
- 家にて
- 事前に自前のPCに環境構築をする
- 環境構築で分からないことをSlackで聞く
というように、非常に仕事で忙しい中、丁寧に対応してもらった。
体験入社当日
- オフィスに行く
- チームに改めて紹介
- 担当者が不慮の寝坊により不在だったが、事前打ち合わせで僕がやる予定のタスクが分かっていたので、勝手にタスクを消化し始める
- チームでランチを食いに行く(経費!!!!!!)
- 午前中のタスクをコミットしてレビューしてもらう間に、別のタスクにとりかかる
- チームのタスクの進捗確認のためのスタンドアップミーティングに参加する
- タスクで取り掛かっていたバグの原因が分かり、修正しようとするも時間切れに焦った結果、完全にUXがぶっ壊れるコードをレビューに出してしまい、迷惑をかけて猛烈に反省する
- 非常に丁寧なレビューをしてもらえて有り難い
- 体験入社のフィードバック会があり、フィードバックをお互いにする
大事な日にこそ寝坊をするのは僕だけじゃなかったという安心感。今思うと、僕の緊張をほぐすための高度な気遣いだったのかもしれない。
感想
- チームメンバーが非常に物腰の柔らかい人たちで仕事がしやすそう
- Slackで技術的な情報の共有が頻繁にされていて最高
- ドキュメントが非常によくまとめられていて、大体ドキュメントどおりにやれば環境ができる
- AWSやGCPなどの色々な技術スタックを利用して、膨大な量のログを処理しているアーキテクチャが面白そうだった
- 技術負債に立ち向かってどんどんコードを良くしている様子が伺えた
- 自分に対してのフィードバックももらえるのでありがたい
- Repro Tech Meetupが色んな話聞けて楽しいし、RubyistならRuby界隈で勢力的に活動する人たちと仕事できるので幸せ
- CTOオブザイヤーや地域Rubyコミュニティのオーガナイザーや発表者がいて福利厚生感ある
- 事前に打ち合わせと環境を作る時間が必要なので、一日体験入社 + αという感じ
- 勢いがあるため、オフィスが人数に追いついておらず物理的に空気が悪い
- 新時代令和なので増床して改善してるはず
一日体験入社はこちらからと書こうと思ったら一日体験入社へのリンクが…ない…!! ということでめちゃめちゃナイスな人柄のVPoEの方のTwitterをはっておく。
threetreeslight (@threetreeslight) | Twitter
株式会社SmartHR
めちゃめちゃ勢いのある人事労務管理を生業とする会社。こちらも人が増えているので、この間ギロッポンに引っ越したらしい。僕が行った時はまだ半蔵門だった。PCはアカウントなど含めて、全てがセットアップされたものを使う。自分のdotfilesがあると便利。
体験入社までの流れ
体験入社のフローがめちゃめちゃ整理されていて、すごい。
体験入社当日
- オフィスに行く
- 朝会(スタンドアップミーティング)に参加して顔合わせ
- 体験入社の担当者がやむを得ない事情で不在だったが、体験入社ガイドブックのおかげで環境構築をすればいいことが分かっていたので、提供されたPCで作業にとりかかる
- 提供されたPCが日本語配列で辛い思いをしていたら、チームメンバーの手厚いサポートにより、英語配列のマジックキーボードとついでにトラックパッドを提供してもらう
- 簡単な文言修正をアサインしてもらい、チームメンバーに説明を受けて作業をする
- チームでランチを食い行く(経費!!!!!!!!)
- 午前中のタスクをコミットしてレビューしてもらう
- 別のチケットをアサインされるも、業務知識がなさすぎて混乱していたら、チームメンバーが一緒に画面見ながら説明してくれ、作業開始
- 実はそんなに簡単な修正ではないのでは説が出て、突然チームメンバーと実装方法について議論を交わす
- スクラムのスプリントプランニングに参加
- マージされた修正をデプロイ
- 終了30分前に体験入社のフィードバックを依頼され、筆が遅すぎて残業をする
- フィードバックを書き終えて「帰ります!」と叫んだ後に、やりかけの作業を引き継ぐためのプルリクエストを作り忘れていて残業をする
残業王に俺はなる!残業をしすぎると残業王というTシャツが回ってくるらしい。
感想
- 開発環境がDockernizeされていてすんなりと開発に入ることが出来て最高
- チームメンバーの物腰が柔らかく仕事がしやすそう
- 僕が混乱している箇所を説明してくれた時に、横について「操作を見てていいですか?」と言われたのが印象的で、慣れない人がどこでひっかかっているか観察するという開発者のプロダクトへの向き合い方が非常によい
- SaaSとして成功するためのプラットフォームを支えるアーキテクチャを考えるのが面白そう
- 実装方針の議論を気軽にできる雰囲気があってうれしい
- 開発からスプリントイベント、さらにはデプロイまで体験できるように設計してあって普段の開発の様子が十分に伺える
- スクラムを実践していて、スプリントプランニングが丁寧
- 一日体験入社のフィードバックを書いたが、自分に対してのフィードバックも頼んだらもらえて有り難い
- PCの日本語・英語配列は事前に聞いてほしかった
- フィードバック書いたので新時代令和には直っているはず、早いほうがカッコいい
自分に対してのフィードバックの一部に反応した様子です。
声が大きくて聞き取りやすいって褒めてもらったのでハリウッド目指します
— レベルがあまりに低い (@terut) 2019年2月25日
他にも仕事への姿勢や「突然設計についてメンバーと議論し始めてウケた」など素直なフィードバックがもらえて有難い。
体験入社はこちらから。
まとめ
2社とも非常に魅力的なので、ぜひ一日体験入社をお勧めしたい。2社ともなぜか普段いるはずの担当者がいなかったりしたのだけど、スムーズに作業できる環境が整っていたし、チームに入りやすいようにしてくれている。担当者がいないのは僕の徳の積み方が足りないからだと思う。体験入社するとよりチームや仕事の進め方の雰囲気がよく分かるので、どんどんやっていき。アフィブログみたいなまとめになってしまったが、本当にオススメなんや…味わってクレメンス。
写真撮ったやろと思って写真探したら一枚もなくて、ブログ書いていいですかとドヤ顔したくせに意識が低い。あまりにレベルが低いと言われても仕方がない。
もし今回の体験日記に書いてあること以外で聞きたいことがある人はTwitterでリプライでもくだされ。
Web APIにおける認可の現状確認 2019 春
最近Web APIの認可について思いを馳せる機会があったのだけど、どの方法で認可を実装するのがスタンダードなのか、そもそもそんなものは最初からないのか、よく分からなくなったので自分なりの考えをまとめることにした。
ファーストパーティのアプリが使うWeb API(プライベートなWeb API)の場合はセッションを使うケースもあるだろうが、セッションを使うケースでは悩むことも少なかったので、ここではアクセストークンを用いた認可にフォーカスして考えてみたい。ケースとしてはユーザー毎にアクセストークンが発行され、Browser-BasedアプリやNativeアプリからWeb APIが叩かれることを想定している。
追記 2019/03/04
認証や認可周りについてよく拝見させてもらっている方にブログで言及していただきました。合わせて読むことをお勧めします。
特にResource Owner Password Credentialsの説明はよく目を通してください。僕が混同している可能性があります。頭の中で整理できたら記事を訂正したいと思ってますが、まだできておらずそのままになっています。すいません。
認証/認可の現状について
普段、開発をしていると色々なサービスがサードパーティへ公開しているWeb API(パブリックなWeb API)をよくさわる都合上、OAuth 2.0を用いた認可の実装、OpenID Connect 1.0を用いた認証/認可の実装の様子を目にすることが多い。それぞれOAuth2とOpenID Connectとここからは呼ぶことにするが、パブリックなWeb APIを作るシナリオを考えている場合はOAuth2、または OpenID Connectのプロバイダになるのがスタンダードだと認識している。ただ多くのサービスで最初に用意するのはプライベートなWeb APIだろう。
ここで一つの疑問が湧いてきた。プライベートなWeb APIの認可はどう実装していくのがスタンダードなのか?ファーストパーティのアプリのためだけにOAuth2やOpenID Connectを実装するのか?
例えばSPAのようなBroswer-Basedアプリに対してのOAuth2について書かれたDraftには以下のようなことが書かれている。
While OAuth and OpenID Connect were initially created to allow third-party applications to access an API on behalf of a user, they have both proven to be useful in a first-party scenario as well.
https://tools.ietf.org/html/draft-ietf-oauth-browser-based-apps-00#section-5
Draftでかつ00ではあるが、OAuth2とOpenID Connectがファーストパーティにとっても有用であるという主張は分かるし、現にAuth0などでもOAuth2を使うことで自分たちのアプリケーションへAPIアクセスを提供できるとドキュメントで言及されている。
その一方で、それなりの割合で独自の認可方式を実装していたりするのを見かける。僕自身も独自の認可方式を実装したことがある。OAuth2の仕様を調べれば調べるほどプロバイダの実装が大変であることが分かり、独自の認可方式を用意するほうが楽なように思えたからだった。そしてOAuth2を実装するライブラリが揃ってきたとは言え、2019年現在でも実装は楽ではないなと思っている。だからこそ認証/認可のマネージドサービスが生まれているんだろう。
独自の認可方式を実装することは楽なのか?
上記で述べたようにOAuth2を実装することはそれなりに大変だなと思ったので、独自の認可方式を実装するならどうなるのかということを改めて考えてみた。例えば以下のようなものがパッと思いつくプリミティブな実装だろう。
- OAuth2で言うところのResource Owner Password CredentialsのようなSomethingでusername/passwordを渡すとアクセストークンのみが払い出される
OAuth2のResource Owner Password Credentialsは以下のようなフローでアクセストークンが発行される。
+----------+
| Resource |
| Owner |
| |
+----------+
v
| Resource Owner
(A) Password Credentials
|
v
+---------+ +---------------+
| |>--(B)---- Resource Owner ------->| |
| | Password Credentials | Authorization |
| Client | | Server |
| |<--(C)---- Access Token ---------<| |
| | (w/ Optional Refresh Token) | |
+---------+ +---------------+
要はこれと同じようなものを実装する。これはめちゃめちゃ実装が楽だと言える。ただOAuth2のResource Owner Password Credentialsの説明を眺めていると、どうやらこれだけでは足りないということが分かってくる。セキュリティ的な問題をクリアするためには以下のようなものを実装したほうがいいだろう。
さらに、Browser-Basedアプリでアクセストークンを使う場合は、セキュアにログイン状態を維持するための仕組みが必要になる。例えばユーザーの認証を通してアクセストークンを更新する仕組みだ。OpenID Connectを実装してSilent Authenticationのような仕組みを用意したり、それに近しい仕組みが必要になる。
これはBrowser-BasedアプリがPublicなクライアントなのでリフレッシュトークンは発行すべきではないからだ。そろそろ役目を終えそうなImplicitでもリフレッシュトークンは発行すべきではなく、もしどうしても発行したいなら頻繁にリフレッシュトークンを変えるような方法を取るように書いてある。もっともファーストパーティのBrowser-Basedアプリではセッションを使うという方法も取れるので必須ではないと思う。
この他に実装上の問題点も分かってくる。
- ファーストパーティのクライアントのなりすましに気づくポイントが少ないことにどう対応するか
- 自然と中間者攻撃の様相を呈していないか
- 独自の実装で生まれうる脆弱性にどう気づくか
これらを考慮しながらアクセストークンの期限、リフレッシュトークン、クライアントの特定方法まで実装してくるとほとんどOAuth2の実装に足を踏み入れ始めているのではないかと思う。これに加えて独自の実装で生まれる脆弱性についても思いを馳せる必要があるが、それを考慮しきれるのかという不安がとにかくヤバイ。Bearトークンを採用しようがJWTを採用しようが考えないといけないことだと思っていて、JWT便利でしょといってリフレッシュの仕組みも用意せず、生存期間の長いアクセストークンを用意しているとかだとかなり問題があるのではないかと思っている。つまり独自の認可方法を用意するのは全然楽ではない。認可それ自体がセキュリティとセットで意味をなすので、そもそも楽な方法などなく歯を食いしばって実装する類のものなのだろう。
ちなみに、OAuth2のRFC6749の中でResource Owner Password Credentialsは以下のように説明されている。
The credentials should only be used when there is a high degree of trust between the resource owner and the client (e.g., the client is part of the device operating system or a highly privileged application), and when other authorization grant types are not available (such as an authorization code).
https://tools.ietf.org/html/rfc6749#section-1.3.3
大事なのは「他のGrantが利用できないとき」という部分で、これはAuthorization CodeがBroswer-BasedなアプリやNativeアプリに対してほとんど場合で適用できることを考えると選択しないほうが好ましいということだと思うし、Nativeアプリに対するOAuth2について書かれたBCP212はAuthorization Code前提で書かれている。
https://tools.ietf.org/html/bcp212#section-4.1
したがって簡単に実装できると思っていたResource Owner Password Credentials方式はOAuth2では限定利用に留める方向になっていて、独自に実装する際はこの限定利用の壁を壊す俺の最強武器を用意する必要があり、セキュリティに明るくない僕には無理ゲーな上に新規プロダクトのコアにほとんどなりえない認証/認可に時間を吸われる結果になるのではという思いに至った。
まとめ
ここまで考えてみると、実装はそれなりに大変だが認可のフローや脆弱性をたくさんの目を使って議論しているOAuth2やOpenID Connectなら仕様は既にあるし、プロバイダになるにあたって気をつけるべきことは論じられているので、ファーストパーティが使うWeb APIだとしてもOAuth2やOpenID Connectを採用しつつ、Authorization CodeやPKCEなど必要最低限の実装を持ったプロバイダを実装するのが2019年春現在考えうる最良の認可なのではないかと思う。あくまで最初に想定しているケースの場合なので、Confidentialなクライアントだけしか存在しない場合だったりするとClient Credentialsのような仕組みで十分なこともあり得るだろう。
途中で湧いた疑問
ちなみにOAuth2を採用してAuthorization Codeを使う場合、ファーストパーティのアプリに対して認可の画面が出てくるのはもしかしたら少し違和感があるかもしれない。ファーストパーティのアプリのみ認可の画面をスキップするとかという話も耳にしたことがあるのだけど、正しい方法はちょっと分からないので知りたい。Client IDが漏れる可能性を考えても、Redirect URIの完全一致を検証することにより、スキップしても問題ないような気がするがどうなのだろうか?
最後に
僕は認証/認可に明るいわけではないので、間違っていたりおかしい箇所についてはぜひアドバイスをくださいと思っている。OAuth2やOpenID Connectを実装しようという結論にしてもめちゃめちゃ自信があって言ってるわけではないので、より良い方法があるならぜひ知りたい。サードパーティが使うWeb APIならOAuth2なり実装するでしょという感じだと思うのだが、ファーストパーティに関してもOAuth2で実装するのが当たり前すぎるのかあまり言及されてない気もする。たぶん当たり前なのかも知れない。あるいは既に当たり前な別の方法があるのかもしれない。基本的に最初から認証/認可系のマネージドサービス使っててハッピーですとか。正直なところ、認証/認可の話をブログに書いたりするのは個人的にめちゃめちゃ勇気が必要だった。知り合いしか見てないと分かっていても。
ロールベースアクセス制御を試せるサンプルを書いた
世の中には便利最高なサイトが存在していて、 SaaSやるにあたっての用意したほうがよい機能群を網羅したサイトがある。
その中で権限管理に関する言及もあって、RBAC(ロールベースアクセス制御)について書かれている。RBACに関してはググれば出てくるので割愛するが、割とこういったスタンダードな実装をしてるケースは個人的な体感ではあまり出会ったことがなくて、組織やロールで権限を判断する実装とかをよく見かける。ロールで権限を判断する実装というのは、例えばManagerというロールだったらこのオペレーションの実行を許可するみたいな感じ。僕自身もそういった実装をしたことがあるが、そういう実装だと割と自由度が低く、すこしイレギュラーなケースではもにょる実装をしてしまうことになりがちだった。RBACで実装しておくと色々応用が効くので便利だと思う。GCPやAWSの権限管理とかもRBACがベースになっている感じがする。
ということで基本となるRBACのプリミティブな実装をRubyで用意して色々実験できると捗るなと思ってそういうサンプルを書いてみた。データベースにおける登場人物は以下のような感じ。
- Users
- Roles
- Permissions
- RolesとPermissionsの交差テーブル(中間テーブル)
あくまでこれらのテーブルはプリミティブな実装にすぎず、テーブルを追加することでユーザーが複数のチームに所属して、チーム毎にメンバーのロールを変えたいとかって要件を表現できるようになる。この辺の詳しい解説はいくらでもあるので、そっちに任せることにする。
サンプルではMarioがAdmin、PeachがManager、LuigiがMemberみたいな感じにしていて、Roleを管理する権限を前提にMarioはRoleのCRUDができる、PeachはRoleのDができないだけ、LuigiはRoleのRができるみたいな感じになってる。
正直Rails界隈ではcancancanみたいなライブラリもあるので、わざわざサンプル書いたことをブログにアウトプットして価値あるのかなとも思うけど、RBACを色々試したい人にとっては参考になるかなと思って筆をとった。
Rubyでの実装を試すruby-sandoxという個人のリポジトリ内にコードがあり、余計なコードまでcloneされるので覚悟してほしい。ぶっちゃけ僕の怠慢です。すいません。
よければ試してみてください。何か僕が間違っていればぜひフィードバックがほしいので、よろしくお願いします。
近況報告
僕の知り合いへ向けての報告です。去年の12月末で前職を退職してフリーランスになりました。ここまで書いて、前回の近況報告でお知らせした無職から職を得た話をしてなかったことを思い出しましたが、また職を失ったのでもうその話はいいですね。
年末の最終出社日から1月中旬ぐらいまで開業準備をしていました。ググればすぐ出てくるんですが、もしフリーランスをやるならちゃんと無職になる前に準備したほうがちょっとだけ幸せになれます。なお僕はしませんでした。僕みたいな雑に生きてるタイプの人間は無職になる前に準備せずとも、たぶんまあいいかで済むので別に準備しなくていいです。開業Freeeとか使えば特に面倒な手続きもなく準備できます。有り難しですね。ただ健康保険の任意継続と開業費や電子帳簿保存の手続きについては調査しときましょう。開業費に関してだけはちょっと失敗したなと思っています。
開業準備も終えたので、とりあえずちょっとだけ仕事をしながら子供との時間を作りたいなと思ってることもあり、現在は時間にすると週1日ぐらい働いていて、プロダクト開発の技術的な部分に関するアドバイザーみたいなことをしてます。これはちょっと特別な事情もあっての仕事で、メインの働き方はプログラマとしてコードを書くという感じをイメージしています。
フリーランスでの仕事をそろそろ探そうかなと思っているので、一応前職で何やってたかぐらいは書いておきます。
- DockerとGolangでのAPIの開発
- Clean Architectureでの設計の改善
- TerraformでのGCPのインフラ管理
- k8sへのアプリケーションのデプロイ
- CircleCI上でのテストを3倍高速化
- RailsアプリケーションのN+1の撲滅
- ドキュメントの整理とそれに関する技術書典への執筆
- 技術的課題に対する方針の決定
- スクラムにおけるプロセスの改善
以上のようなことを大まかにはやってました。 主にサーバーサイドの仕事をやっていましたが、以前はiOSのアプリ開発などもやってました。最近はフロントエンドのキャッチアップができてなかったので、暇な時間でTypeScriptやら触っています。職歴はLinkedInとかにまとめてあります。
https://www.linkedin.com/in/terunori-togo/
これはオブラートに包んで言うと「僕に仕事をください!!!!!1」ということです。あとサバンナに入ってみたいんですが、誰か招待してくれませんか…ぼっち力が高くてですね…。
どうでもいい話をすると職があったときは定期的に職場の人を誘ってフットサルをしてたんですが、フリーランスの人ってフットサルとかどうしてるんですか?
Arch Linuxでffmpegの依存解決に失敗する
今日、ArchLinuxのパッケージをいつものようにアップデートしようとしてハマった。解決策がネット上に見当たらなかったので書いておく。
遭遇したエラーは以下のような感じだった。
$ yaourt -Syua [sudo] password for terut: :: Synchronizing package databases... core is up to date extra is up to date community is up to date multilib is up to date archlinuxfr is up to date error: failed to prepare transaction (could not satisfy dependencies) :: Starting full system upgrade... resolving dependencies... looking for conflicting packages... error: failed to prepare transaction (could not satisfy dependencies) :: unable to satisfy dependency 'libx265.so=160-64' required by ffmpeg No database errors have been found!
どうやら依存が上手く解決できないように見える。
ffmpegのバージョンは 4.0.2-3 が入っていて、ffmpegのパッケージのバグページを見てみると 4.0.2-6 で直るらしいことが分かった。
データベースのアップデートをしてもffmpegの 4.0.2-4 しかなかったので、仕方なくffmpegのパッケージサイトからミラー経由でダウンロードして直接入れた。
Arch Linux - ffmpeg 1:4.0.2-6 (x86_64)
右上の [Download From Mirror] からダウンロードできる。 ダウンロードしたら直接インストールしてしまう。
$ yaourt -U ~/Downloads/ffmpeg-1_4.0.2-6-x86_64.pkg.tar.xz resolving dependencies... looking for conflicting packages... error: failed to prepare transaction (could not satisfy dependencies) :: installing x265 (2.9-1) breaks dependency 'libx265.so=160-64' required by ffm peg loading packages... resolving dependencies... looking for conflicting packages... Packages (2) x265-2.9-1 ffmpeg-1:4.0.2-6 ...
エラーが出ているが、これは現在のffmpegのバージョンによるエラーっぽい。ffmpegの 4.0.2-6 は libx265.so=165-64 に依存しており、x265-2.9.1 は libx265.so=165-64 として提供している。依存関係からすると同時にインストールしてしまえば問題なさそうだったのでインストールした。
結果として、ffmpegも libx265.so=165-64 版の共有ライブラリに依存するようにインストールされていたので良さそうに見える。
ひとまずこれで全体のアップデートができるようになった。
すでに ffmpeg の 4.0.2-6 がデータベース側にも反映されてるので、同じように依存でアップデートできないぞという人は参考にしてほしい。
GCPの検証・本番環境をTerraformで上手く管理する方法
Goodpatch Advent Calendar 2017 - Qiita の24日目は @terut がお送りします。
さてさて12月24日ですが、みなさんリア充してますか? 24日は若者に書かせるわけにいかないので、24日のアドベントカレンダーはおっさんの仕事というのが相場のようです。
最近GCPの管理のためにTerraformに入門しました。入門しながら思ったのが、検証の目的に合わせて複数の環境を作るのが面倒くさいということです。Terraformで管理する場合、Terraform用のサービスアカウントを用意したりするのですが、普通にやってしまうとプロジェクト毎にTerraform用のサービスアカウントを準備しなくてはならず、さらにビリングアカウントへの紐付けをある特定の人へお願いしたりという作業が発生します。もうちょっといい方法がないものかと思って色々と調査をしたところ、GCPのリソースは階層構造を持っておりIAMポリシーは継承されるので、それを上手く使うのがよさそうな雰囲気を感じて、試してみました。
TL;DR
- Managing GCP Projects with Terraform | Google Cloud Platform Community | Google Cloud Platform を読みましょう
- Terraformのworkspaceを上手く使って環境毎にtfstateファイルを管理しましょう
前提条件
組織で管理する中でどのように階層と権限を設計するかという話だったので、一応環境を揃えるために組織で管理する環境を作りました。自分のドメインがあれば、Cloud Identityを使って申請できます。ドメインを自分のものであると証明するために、DNSへTXTレコードかCNAMEを登録する必要がありますが、15分程度あれば登録して、組織で管理された環境を作れます。なおドメインに関連したアカウントを作る必要があり、そのアカウントにも$300が有効にできるので、今回のこの方法でお金がかかることはないですが、ロボットでないことを証明するためにクレジットカードは入れなければなりません。
環境の構築方法
基本的は上に紹介した Managing GCP Projects with Terraform | Google Cloud Platform Community | Google Cloud Platform の流れに沿って環境を作っていくことになります。IAMのポリシーの継承を上手く使うため、Adminプロジェクトを作り、その中でTerraformで管理するためのサービスアカウントを発行し、他のプロジェクトを管理する権限を与え、すべてのプロジェクトをそのサービスアカウントで管理するというイメージになります。
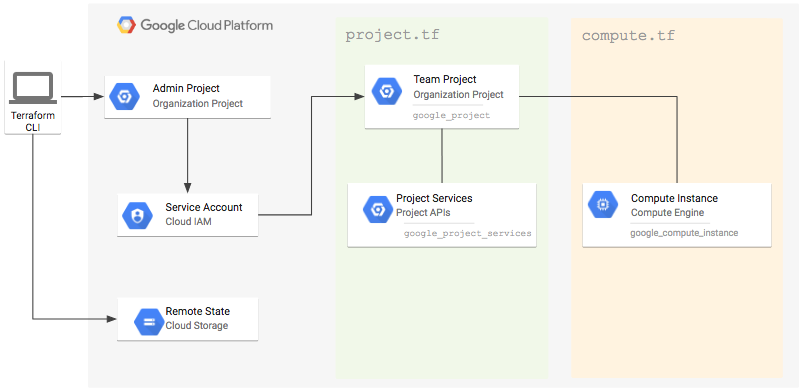
一通りリンクの手順を試してみると分かりますが、このままではAdminプロジェクトで管理された一つのtfstateファイルに変更が反映されていきます。そこでTerraformのworkspaceの出番です。
$ terraform workspace new staging
これを実行するとAdminプロジェクトのCloud Storage上には staging.tfstate が出来ているのが分かると思います。workspaceの値はtfファイル内で参照できるので、ディレクトリでtfstateファイルの置き場所を分けたりといったことも出来そうです。Terraformのworkspaceを上手く使いながら、一つのTerraform用のサービスアカウントを用意することで、すべてのプロジェクトが管理できるような感じがしますね。
まとめ
GCPのリソース階層へのIAMポリシーの継承などを使い、管理用のサービスアカウントを用意することで、すべてのプロジェクトで同じような手作業をするということが避けられ、ほぼすべてをTerraformに任せられそうです。入門したてなので、もっといい方法や普通はこうやるんやでなど、色々なアドバイスをお待ちしてます。
そういえばまったく関係ないんですが、12月25日は僕の誕生日でした。いつものやつ貼っておきますね!
「ですます」であまり書かないので不思議な気持ちやな〜。
画像ビューアを作ってみている話
macOS用の見開き画像ビューアがほしいなぁと思い、車輪の再発明をすべく画像ビューアを作り始めた。最初Electronで作っていて、最小の機能の付いたそれっぽいものを作った段階でいかんともしがたい問題にぶつかり、一旦、他の技術も見てみようと、QtのGoバインディングで作り直してみてる。
成果
何はともあれ成果です。
Electronの問題
Electronで一通り作り終えた時に、サムネイル画像のキャッシュなどを作らずにオリジナルで表示してたので、メモリの使用量がどんなものになるのか気になって調べた。いろいろ調べているうちに、macOSで画像を切り替えまくると爆速でメモリが1.5GBぐらいまで増加していくことが分かった。画像自体は全体で110MBほどなのでいくら何でもひどい。待っていても開放される気配は一切なく、Chromeのプロファイラを見た限りではJS Heapなどはたいしてメモリを食っていなかったのとGCは走ってるように見えたので、DOMリークなのかなと思っている。とにかく何をしても解消しなかった。Chromiumの複数バージョンを試して、それっぽいバグは再現できたけど、既にバグ報告はしてあり最新版では再現しない。加えてWindowsとLinuxでは特に問題なくてメモリも開放されてるので、内部のChromiumのバージョンが上がったら直りそう。ちなみに次のバージョンでは直ってなかった。
QtのGoバインディング
上記のやつを使っている。ただデバッグがやりにくくて萎えそう。独特の文法みたいなものが必要にはなるものの、サンプルも結構用意してあるので、それを読めば割とイケる。
https://github.com/therecipe/qt/tree/master/internal/examples
Qt自体はQMLというインターフェースのためのマークアップ言語を用意していて、Javascriptが利用可能でJavascriptにロジックを追いやったりできるので、そこはとっつきやすい。ちなみにQtの最新版である1.9.1を使っていたら、QMLのImageでメモリリークが起こっていて、笑うしかなかった。バージョンを下げて対応した。
今後
QtのGoバインディングのデバックについて、もうちょっといいやり方がないか調べたりして、知見ためたい。もう少し試してみて、ElectronかQtのGoバインディングにするか決めようと思っている。